日文乱码转换 Java 的具体实现方法
在软件开发中,经常会遇到处理不同字符编码的问题,特别是当涉及到日文等非拉丁字符时。将详细探讨日文乱码转换 Java 的具体实现方法。
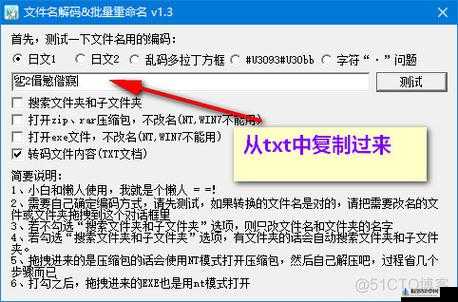
我们需要了解一些基本概念。字符编码是将字符映射到数字的方式,不同的编码方案可能会对相同的字符使用不同的数字表示。常见的字符编码包括 ASCII、UTF-8、UTF-16 等。
在 Java 中,为了实现日文乱码的转换,我们可以采取以下步骤:
第一步,确定输入的日文文本的原始编码。这通常可以通过查看数据源或与相关方沟通来确定。
第二步,根据原始编码读取日文文本。使用适当的输入流,如 `BufferedReader`,并指定正确的编码。
第三步,进行编码转换。可以使用 Java 提供的编码转换类和方法。例如,使用 `Charset` 类来获取和操作不同的字符集。
第四步,将转换后的文本输出到所需的目标编码。
以下是一个示例代码,展示了如何将日文乱码从一种编码转换为另一种编码:
```java
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.nio.charset.Charset;
public class JapaneseEncodingConversion {
public static void main(String[] args) {
// 原始编码
String sourceEncoding = "Shift_JIS";
// 目标编码
String targetEncoding = "UTF-8";
try (BufferedReader reader = new BufferedReader(new FileReader("japanese.txt", Charset.forName(sourceEncoding)))) {
StringBuilder content = new StringBuilder();
String line;
while ((line = reader.readLine())!= null) {
content.append(line).append("\n");
}
// 进行编码转换
String convertedText = new String(content.toString().getBytes(sourceEncoding), targetEncoding);
// 输出转换后的文本
System.out.println(convertedText);
} catch (IOException e) {
e.printStackTrace();
}
}
```
在上述示例中,我们首先指定了原始编码和目标编码。然后,通过读取文件中的日文文本,并使用相应的编码进行转换,最后将转换后的文本输出。
需要注意的是,在实际应用中,可能需要根据具体情况进行更多的错误处理和优化。例如,对于可能存在的非法字符或不支持的编码情况,需要进行适当的处理。
还可以利用一些第三方库来简化编码转换的过程。这些库通常提供了更方便和高效的方法来处理各种字符编码问题。
通过理解字符编码的原理,并结合 Java 提供的工具和方法,我们可以有效地实现日文乱码的转换。这对于处理多语言文本和确保数据的正确显示和处理至关重要。在实际开发中,要根据具体需求和情况选择合适的方法和工具,以获得最佳的转换效果。希望对你在处理日文乱码转换 Java 方面有所帮助。